
If one takes a look at the current Xeon/Desktop processor roadmap and the historic change to multicore system design a decade ago, one thing is pretty evident.
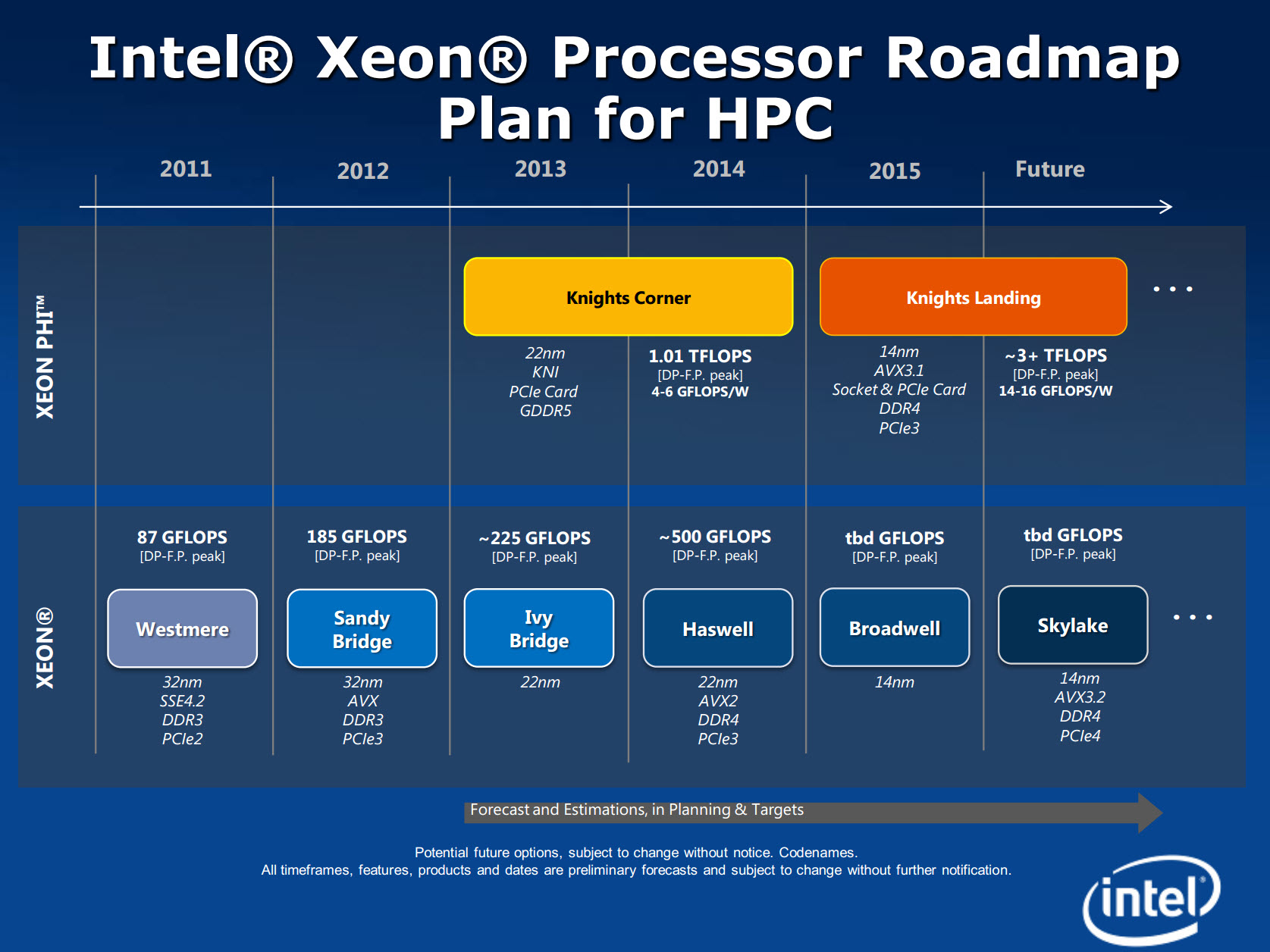
Intel Xeon Roadmap
The Parallelism on offer at the node (single server) level is increasing at an unprecedented rate. This is going to increase and trickle down to further levels of granularity in the coming years.

Node Example [pic borrowed from ‘the register’]
Gone are the days when new processors brought with it an instantaneous increase in performance for applications that were written a decade (#justSaying) ago. If we need any increase in performance, we need to have a plan to ensure that the software that runs on the flashy new server knows how to engage all the available resources.
This takes precedence like never before as the processor manufacturers are now accelerating to offer processors which are not just multi core but many core. The many core systems will have 70+ cores on a single die.
What are the available resources?
The processor is an inherently parallel machine. Starting at the micro-architecture level, the processor achieves what it does by trying to do more than one thing in parallel.

Broadwell DE Block Diagram; Pic borrowed from Anandtech via Intel
The above figure shows the block diagram of Broadwell DE SoC from Intel, the division of the processor into multiple cores and the infrastructure to connect those and feed the data into it is pretty evident.
We can now classify the available compute resources in a processor (from a 1000 ft. ) to be as below

Processor is a single computing component with two or more independent actual processing units (called “cores“).
The cores may optionally be designed to have one or more Hardware threads that enable better utilisation of the processor under some circumstances. They may be exposed to/by the operating system as appearing to be additional cores (“hyperthreading”).
The current generation of processors also include what are known as SIMD instructions (AVX 512, AVX.., SSE4, SSE..) in the instruction set which execute an instruction at more than one data point at the same time. This is in addition to Instruction Level Parallelism and Superscalarity that the processors offer..
(All the above resources need data for it to be functional and hence the memory bandwidth becomes a very important metric, the other resources like caches play a critical role to ensure that the data is fed to the processors and minimize the idle time).
Once we figure out a methodology for our software to effectively utilize all the above mentioned resources and prove that the software can effectively scale out to more than one node – we can the further scale up to chassis -> rack -> datacenter

Chassis

Rack Example: SGI UV 300

Titan Supercomputer
Scaling at each of these levels comes with its own challenges. If our software scales well at all these levels of granularity, it can be considered to be a High Performance Computing ready code.
So, What is Performance Engineering?
Performance Engineering is the art and science of crafting the code such that all the available compute resources are utilized to its fullest potential (at the level at which you are operating, node/chassis/rack or data center)
[This is the first article in a series of upcoming articles on Performance Engineering]
